개요
구조가 비슷한 두 머신러닝 기법을 알아볼 것이다. RandomForestRegressor 와 GradientBoostingRegressor.
두 모델 모두 앙상블 (여러 하위 모델들을 학습시켜 하나의 강한 모델을 만드는 기법) 에 포함된다.
기존 모델들의 과적합이나 편향을 없애기 위해 여러 모델을 시도하는 것은 중요하다.
그렇기에 우리는 다양한 모델을 알아두어야 된다고 생각한다. 데이터 문해력을 위해!
RandomForestRegressor
기존의 의사결정 나무는 하나의 큰 나무에 여러 가지 질문을 넣어서 모델을 구성한 후,
모든 데이터를 넣어 결과를 보는 방식이라고 축약하여 설명할 수 있다.
처음부터 최적의 질문으로 시작한 후, 단계별로 다양한 질문을 거친다.
그렇기에 과하게 정확한, 과적합 우려가 발생한다고 볼 수 있다.
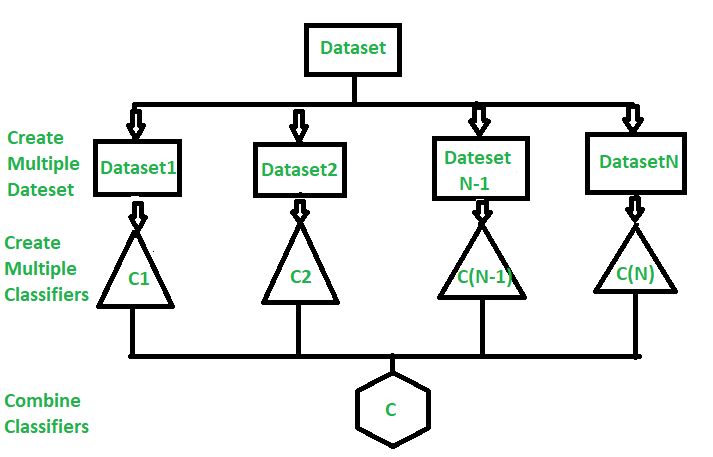
RandomForest는 과적합을 3가지 특징으로 해결한다.
- Boosting : 작은 나무 여러 개에 "중복을 허용하여" 데이터를 분할시켜 준다. 이는 편향을 올려준다.
- Random Features : 무작위의 질문을 작은 나무들에게 준다.
- Voting : 하나의 결과 대신, 나무들 여러 개의 결과를 모두 고려한다.
마지막의 Voting 이 다수결 방식이면 `RandomForestClassifier` 이고, 평균 방식이면 Regressor 이다.
예시 코드는 다음과 같다.
import pandas as pd
df = sns.load_dataset('healthexp')
df.head()👉 데이터를 Seaborn 에서 받아준다.
df1 = pd.get_dummies(df)
df1.head()👉 중요한 코드이다. 해당 데이터셋은 국가라는 범주형 컬럼이 있었기에, 이를 True/False 로 나타내준다.
X = df1.drop(['Spending_USD'], axis = 1)
y = df1['Spending_USD']👉 drop 코드를 통해 종속변수만 제외한 독립변수 입력.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.2)👉 데이터 쪼개기.
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
rfr.fit(X_train,y_train)
y_pred = rfr.predict(X_test)👉 임포트 및 학습은 LinearRegresson 같은 기본 모델과 같다고 보면 된다.
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
print(mean_absolute_error(y_pred,y_test))
print(mean_squared_error(y_pred,y_test))
print(r2_score(y_pred,y_test))👉 수치들 확인해주기. 물론 좋은 수치가 아닐 수도 있다. 그렇기에 다양한 모델을 알아놔야 하는 법!
GradientBoostingRegressor
RFR이 기존 의사결정 나무의 과적합을 해결하려는 모델이였다면, 이 모델은 잔차를 줄여나가려고 한다.
부스팅(Boosting) 이란, 여러 개의 모델을 순차적으로 학습시키면서 이전 모델을 계속 개선해나가는 것을 의미한다.
의사결정 나무 하나로는 부족한 경우, 계속해서 모델을 개선해나가면 된다.
잔차를 개선해나가는 방법으로 경사하강법(Gradient Descent)을 사용하는 것이 GradientBoostingRegressor이다.
이전 모델의 부족함을 경사하강을 통해 채워나가기에, 과할 경우 과적합의 우려가 존재한다.
코드는 다음과 같다.
만약 수치형 데이터가 아닌 범주형 데이터가 있는 경우, get_dummies 를 수행한다.
from sklearn.ensemble import GradientBoostingRegressor
gbr = GradientBoostingRegressor()
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
관련 포스팅
[파이썬] 미국 경제 데이터셋으로 머신러닝 배우기 2 <경사 하강법>
데이터R의 ggplot2 라이브러리의 "economics" 데이터를 활용했습니다. https://ggplot2.tidyverse.org/reference/economics.html US economic time series — economicsThis dataset was produced from US economic time series data available from h
skrrdevlog.tistory.com
'Coding & Data Analysis > Python' 카테고리의 다른 글
| [파이썬] 분류 모델을 위한 EDA/학습/평가/파라미터튜닝 : 심장병 데이터셋 (0) | 2025.03.23 |
|---|---|
| [파이썬/Python] Seaborn + Matplotlib 으로 시각화 총정리 (1) (0) | 2025.01.12 |
| [Python/파이썬] 미국 경제 데이터로 배우는 머신러닝 <K-평균> (5) | 2025.01.09 |
| [파이썬] iris 데이터셋으로 머신러닝 배우기 <로지스틱 회귀> (1) | 2025.01.07 |
| [오답노트] Python에서 for 문으로 matplotlib 그래프 겹치기 w. 머신러닝 (1) | 2025.01.05 |