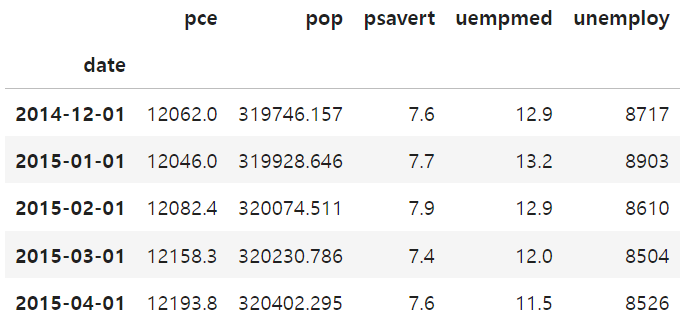
데이터
R의 ggplot2 라이브러리의 "economics" 데이터를 활용했습니다.
https://ggplot2.tidyverse.org/reference/economics.html
US economic time series — economics
This dataset was produced from US economic time series data available from https://fred.stlouisfed.org/. economics is in "wide" format, economics_long is in "long" format.
ggplot2.tidyverse.org
경사하강법
x = df.loc[:,'pce'].values.reshape(-1,1)
y = df.loc[:,'psavert'].values.reshape(-1,1)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(x_train_scaled,y_train)일반적인 LinearRegression 함수는 RSS(Residual Sum of Squares)의 최소화를 통해 최적화를 한다.
예측된 값과 실제 값의 차이를 최소화하는 방식으로 직선을 구하는데,
이상치에 취약하고 규모가 커질수록 계산량이 매우 늘어난다.
그래서 사용할 수 있는 다른 회귀분석 방법이 경사하강법(Gradient Descent) 이다.
손실 함수의 기울기를 구하고, 경사의 반대 방향으로 계속 이동시켜 극값에 이를 때까지 반복시키는 것이다.
손실 함수는 아래로 볼록한 함수이기에 극값 = 최솟값이다.

데이터 스케일링
이러한 방법은 규모가 큰 데이터에서도 무리없이 계산을 수행할 수 있지만,
기존과도 비슷하게 이상치에 취약하다는 단점이 있다. 기울기가 한번 튀게 되면 걷잡을 수 없다.
그래서 데이터를 표준정규분포에 따르게끔 만드는 과정을 "스케일링(Scaling)" 이라고 한다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_test_scaled = scaler.transform(x_test)➡️ fit_transform 함수를 통해 데이터를 표준화한다.
➡️ 독립변수가 기울기에 영향을 미치기에 독립변수만 수행한다. 종속변수는 오차 계산용.
이러한 스케일링 과정은 경사하강법에서는 필수이고, 머신러닝 모델의 학습 전에 일반적으로 진행한다.
모델 생성 및 비교
from sklearn.linear_model import SGDRegressor
sr = SGDRegressor(max_iter=1000, eta0=0.001, verbose=1)
sr.fit(x_train_scaled,y_train.flatten())여기서 경사 하강법의 개념 몇 가지를 알아야 한다.
- 에포크(Epoch) : 데이터 전체 를 활용해 손실 함수의 그래프를 타고 내려가는 한 주기
- 학습률 : 한 번 학습 할 때 이동하는 정도
에포크의 최대 수행 횟수를 max_iter, 학습률을 eta0, 학습 과정 표시 여부를 verbose 로 조절한다.
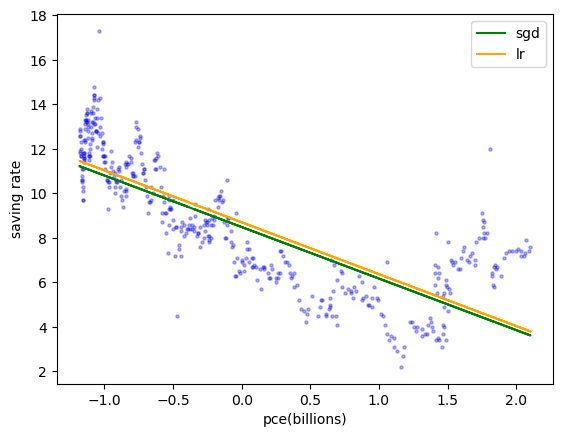
plt.scatter(x_train_scaled,y_train, s = 5, alpha = 0.3, c = 'blue')
plt.plot(x_train_scaled,sr.predict(x_train_scaled), c = 'green', label = 'sgd')
plt.plot(x_train_scaled,reg.predict(x_train_scaled), c = 'orange', label = 'lr')
plt.xlabel('pce(billions)')
plt.ylabel('saving rate')
plt.legend()
plt.show()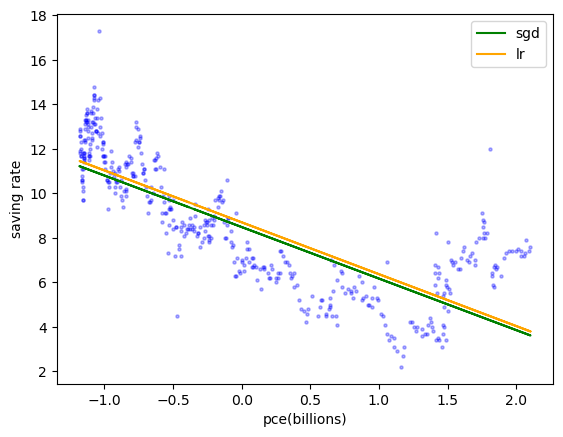
print(sr.t_)
print(sr.score(x_test_scaled,y_test))➡️ sr.t_ : 경사하강법 모델의 학습 횟수
'Coding & Data Analysis > Python' 카테고리의 다른 글
| [파이썬] airquality 데이터셋으로 머신러닝 배우기 <다항 회귀> (1) | 2025.01.04 |
|---|---|
| [파이썬] iris 데이터셋으로 머신러닝 배우기 <다중선형회귀 & 평가지표> (0) | 2025.01.02 |
| [파이썬] 미국 경제 데이터셋으로 머신러닝 배우기 <선형회귀> (1) | 2024.12.27 |
| 파이썬 데이터 분석 쌩 기본기 : matplotlib 시각화 기초 (2) (1) | 2024.12.26 |
| 파이썬 데이터 분석 쌩 기본기 : matplotlib 시각화 기초 (1) (0) | 2024.12.26 |