로지스틱 회귀 (Logistic Regression)
단순 선형회귀, 다중 선형회귀, 다항 회귀 모두 수치적인 데이터를 다뤘다면,
로지스틱 회귀는 범주형 데이터를 다룬다. 독립변수에 따라 종속변수가 어디로 분류되어야 하는가의 문제.
애초에 "Logistics" 가 물류를 의미하는 만큼 닉값을 하는듯..
원리는 간단하게 보면 다음과 같다.

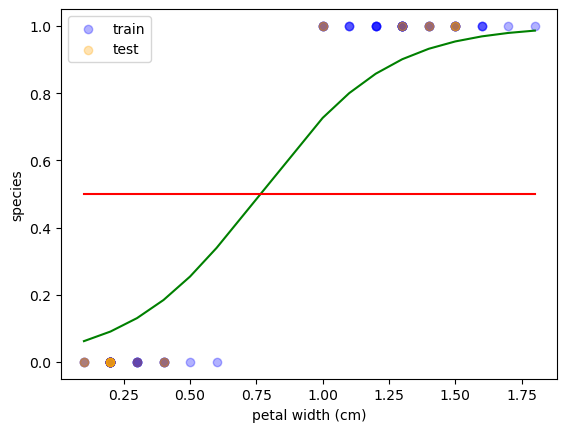
선형회귀는 값 그 자체를 y축에 표시하지만, 로지스틱 회귀는 y축에 확률을 표시한다.
그리고 확률이 50%가 넘어가는지의 여부에 따라 범주를 구분한다.
위에 표시된 곡선은 "시그모이드 함수(Sigmoid Function)" 이라고 부른다.
데이터 및 전처리
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df['species'] = iris.target
filter = df['species'] == 2
df = df[-filter]
df.head()사이킷런 내장 데이터에서 iris를 꺼내왔고, 범주를 2개로 맞추기 위해서 2인 수치를 제거.
X = df.loc[:,'petal width (cm)'].values.reshape(-1,1)
y = df.loc[:,'species'].values.reshape(-1,1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.2)훈련 데이터와 검증 데이터 분리.
sorted_idx1 = np.argsort(X_train.flatten())
X_train = X_train[sorted_idx1]
y_train = y_train[sorted_idx1]
sorted_idx2 = np.argsort(X_test.flatten())
X_test = X_test[sorted_idx2]
y_test = y_test[sorted_idx2]모델의 시각화를 위해 np.argsort 함수를 활용하여 인덱싱.
모델링
from sklearn.linear_model import LogisticRegression
log = LogisticRegression()
log.fit(X_train,y_train.flatten())LogisticRegression 을 import 해서 선형회귀와 동일하게 fit 해주면 된다.
종속변수를 1차원으로 맞추기 위해 flatten 메서드 추가.
print(log.predict([[1]]))
print(log.predict_proba([[1]]))
print(log.score(X_test,y_test))predict 와 score 은 선형회귀와 비슷하게 작동한다.
predict_proba : 특정 수치를 집어넣게 되면 그 수치가 0으로 분류될지, 1으로 분류될지에 대한 확률을 리턴한다.
0으로 분류, 1으로 분류 모두 제공하기에 2차원 array를 리턴한다고 보면 된다.
# sigmoid function (exp : exponential, e^x)
p = log.predict_proba(X_train)[:,1]
p = 1 / (1-np.exp(log.coef_*X_train + log.intercept_))위의 predict_proba 를 활용해서 확률을 y축으로 제공하는 시그모이드 함수를 구현한다.
두 코드 모두 동일한 값을 제공한다. 시그모이드 함수의 수식은 다음과 같다.

np.exp는 자연상수e 의 지수에 값을 집어넣을 수 있는 함수이다.
시각화
plt.scatter(X_train,y_train, c = 'blue', alpha = 0.3, label = 'train')
plt.scatter(X_test,y_test, c = 'orange', alpha = 0.3, label = 'test')
plt.plot(X_train,p, c = 'green')
plt.plot(X_train, np.full(len(X_train), 0.5), c = 'red')
plt.xlabel('petal width (cm)')
plt.ylabel('species')
plt.legend()
plt.show()참고로 np.full과 len을 사용한 코드는, 확률이 0.5가 되는 그래프를 표현한다.
np.full : 특정 값으로 채우는 array를 리턴.

평가치
y_pred = log.predict(X_test)
print(y_pred)
print(y_test.flatten())# array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1])
# array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1])모델의 score가 1이 나왔기 때문에, 모델의 예측이 완벽한 것을 볼 수 있다.
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
cm조금 더 구체적인 지표로 혼동 행렬(Confusion Matrix)을 제시할 수 있다.
로지스틱 회귀의 예측 결과로 TN, FP, FN, TP 를 차례대로 출력한다.
- TN(True Negative) : 예측 결과가 맞고, 0으로 분류
- TP(True Positive) : 예측 결과가 맞고, 1으로 분류
- FN(False Negative) : 예측 결과가 틀렸고, 0으로 분류 (사실은 1임)
- FP(False Positive) : 예측 결과가 틀렸고, 1으로 분류 (사실은 0임)
# array([[11, 0],
# [ 0, 9]], dtype=int64)출력 결과. score가 1이기에 TRUE값만 존재.
관련 포스팅
[파이썬] 미국 경제 데이터셋으로 머신러닝 배우기 <선형회귀>
데이터R의 ggplot2 라이브러리의 "economics" 데이터를 활용했습니다. https://ggplot2.tidyverse.org/reference/economics.html US economic time series — economicsThis dataset was produced from US economic time series data available from h
skrrdevlog.tistory.com
'Coding & Data Analysis > Python' 카테고리의 다른 글
| [파이썬/Python] Seaborn + Matplotlib 으로 시각화 총정리 (1) (0) | 2025.01.12 |
|---|---|
| [Python/파이썬] 미국 경제 데이터로 배우는 머신러닝 <K-평균> (5) | 2025.01.09 |
| [오답노트] Python에서 for 문으로 matplotlib 그래프 겹치기 w. 머신러닝 (1) | 2025.01.05 |
| [파이썬] airquality 데이터셋으로 머신러닝 배우기 <다항 회귀> (1) | 2025.01.04 |
| [파이썬] iris 데이터셋으로 머신러닝 배우기 <다중선형회귀 & 평가지표> (0) | 2025.01.02 |