데이터
이번 글에서는 범주형 데이터를 사용하는 다중선형회귀를 다루기에, 수치와 범주를 모두 포함하는
유용한 데이터셋인 R의 iris 를 활용합니다.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df['species'] = iris.target
df['species'] = df['species'].replace({0:'Setosa',1:'Versicolor',2:'Virginica'})사이킷런에서도 iris를 내장데이터셋으로 가지고 있기에 스근하게 가져와주기..
load_iris 함수를 사용해서 iris 객체를 만들어줍니다.
- iris.data : 2차원 array 를 리턴합니다. 그렇기에 pd.DataFrame 으로 df 객체화.
- iris.feature_names : 말 그대로 피처(독립변수)들의 이름 = 열 이름
- iris.target : 타겟(종속변수) = 추측해보건대.. iris를 로지스틱 회귀 연습용으로 넣지 않았을까..
One-Hot Encoding
범주형 데이터를 다루는 방법에는 원 핫 인코딩이 있습니다.
간단하게 설명하자면, 데이터를 해당 유무 (0 or 1) 형식으로 바꾸고 나서 나오는 문제가 있는데요,

소위 말하는 "다중공선성" 문제입니다.
독립변수들 간의 관계는 독립으로 지켜져야 회귀분석이 원활하게 이루어질 수 있지만, 위의 예시에서는
X1 + X2 + X3 = 1 이라는 관계가 항상 성립합니다. 그렇기에
열 하나를 없애고 난 후, (0,0) 이라는 값을 없어진 열의 몫으로 대체합니다.
모델 생성
X = df.iloc[:,[0,1,4]].values.reshape(-1,3)
y = df.iloc[:,2].values.reshape(-1,1)독립변수는 sepal length, sepal width, species(범주)로 잡았고요, 종속변수는 petal length 입니다.
values와 reshape를 통해 2차원 array 로 만들어줍니다. 사이킷런이 좋아하는 데이터 형식입니다.
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers = [('encoder',OneHotEncoder(drop = 'first'), [2])],
remainder = 'passthrough')
X = ct.fit_transform(X)
X원 핫 인코딩을 수행해줍니다.
- ColumnTransformer 와 OneHotEncoder 를 동시에 활용합니다.
- 'encoder' : 인코딩을 할거야.
- OneHotEncoder(drop = 'first') : 범주형 데이터 3개 중 알파벳 순으로 정렬한 첫 번째를 없앨거야.
- [2] : 범주형 데이터는 3번째 열에 있어.
- ct라는 트랜스포머(?)를 만든 후, 독립변수를 fit_transform에 넣어서 인코딩을 완료합니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.2)
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)
y_pred = reg.predict(X_train)
print(reg.coef_)
print(reg.intercept_)
print(reg.score(X_test,y_test))전 포스팅과 비슷하게, 데이터 나누고, 모델 만들고, 예측값 구하고, 기울기와 절편 및 평가지표를 구합니다.
특이한 점이 있다면, 다중 선형모델이기 때문에 coef_ 기울기가 독립변수의 개수인 4개로 나온다는 거?
[[ 2.16922566 3.06840297 0.63461733 -0.02690226]] = 기울기
[-1.62287686] = 절편
시각화의 어려움
plt.scatter(X_train[:,2],y_train)
plt.plot(X_train[:,2],y_pred)
plt.show()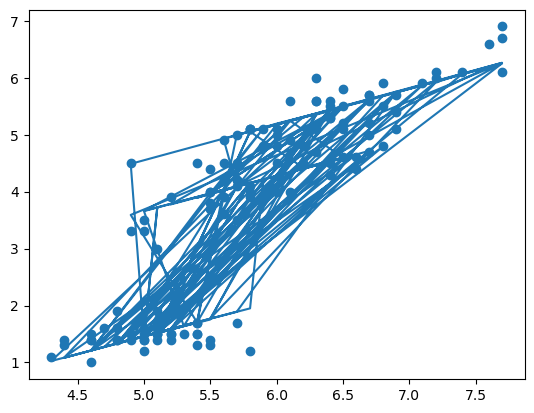
다중선형 모델은 단순한 직선 모형으로 시각화하기엔 변수들이 너무 많습니다.
다른 변수들을 평균값이나 중앙값으로 고정시키는 코드를 수행하고 나서
인위적으로 시각화하는 것은 가능함.
평가지표
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import root_mean_squared_error
from sklearn.metrics import r2_score
print(mean_absolute_error(y_train,y_pred))
print(mean_squared_error(y_train,y_pred))
print(root_mean_squared_error(y_train,y_pred))
print(r2_score(y_train,y_pred)) #r2 = reg.score- mae(mean_absolute_error) : 잔차의 절댓값을 평균낸 것.
- mse(mean_squared_error) : 잔차 제곱을 평균낸 것.
- rmse(root_mean_squared_error) : mse 의 루트값.
- r2_score : reg.score 에서 나오는 값과 동일하며, 1에 가까울수록 모델의 성능이 좋습니다.
'Coding & Data Analysis > Python' 카테고리의 다른 글
| [오답노트] Python에서 for 문으로 matplotlib 그래프 겹치기 w. 머신러닝 (1) | 2025.01.05 |
|---|---|
| [파이썬] airquality 데이터셋으로 머신러닝 배우기 <다항 회귀> (1) | 2025.01.04 |
| [파이썬] 미국 경제 데이터셋으로 머신러닝 배우기 2 <경사 하강법> (1) | 2024.12.30 |
| [파이썬] 미국 경제 데이터셋으로 머신러닝 배우기 <선형회귀> (1) | 2024.12.27 |
| 파이썬 데이터 분석 쌩 기본기 : matplotlib 시각화 기초 (2) (1) | 2024.12.26 |